
Test, fix, repeat. Debugging code with agentic loop is a breeze
Full-stack website generator series part 2

In part 1, I described building the backbone of a full-stack website generator. Debugging was left till the very end, in a chatbot format, where user manually pastes in error messages encountered while spinning up the app and asks the AI agent (who has context of the entire codebase) to suggest fixes. This debugging process took me around 6 hours, and it was a rather stressful 6 hours.
It would be a lot easier if the agent has direct access to all error messages and console logs via some sort of integration. And it would be a lot faster if we could run this test→debug_error→fix_code→test_again loop continuously until the code becomes bug free.
To enhance the full-stack website generator, I built an agentic loop to automatically test and fix the backend codes. For this part 2 of the series, I also wanted to see how different LLMs would perform to this fairly challenging task; especially with OpenAI’s latest o1 model since I just got access to its API.
Before we look at the results, here is an illustration of the agentic debug loop:
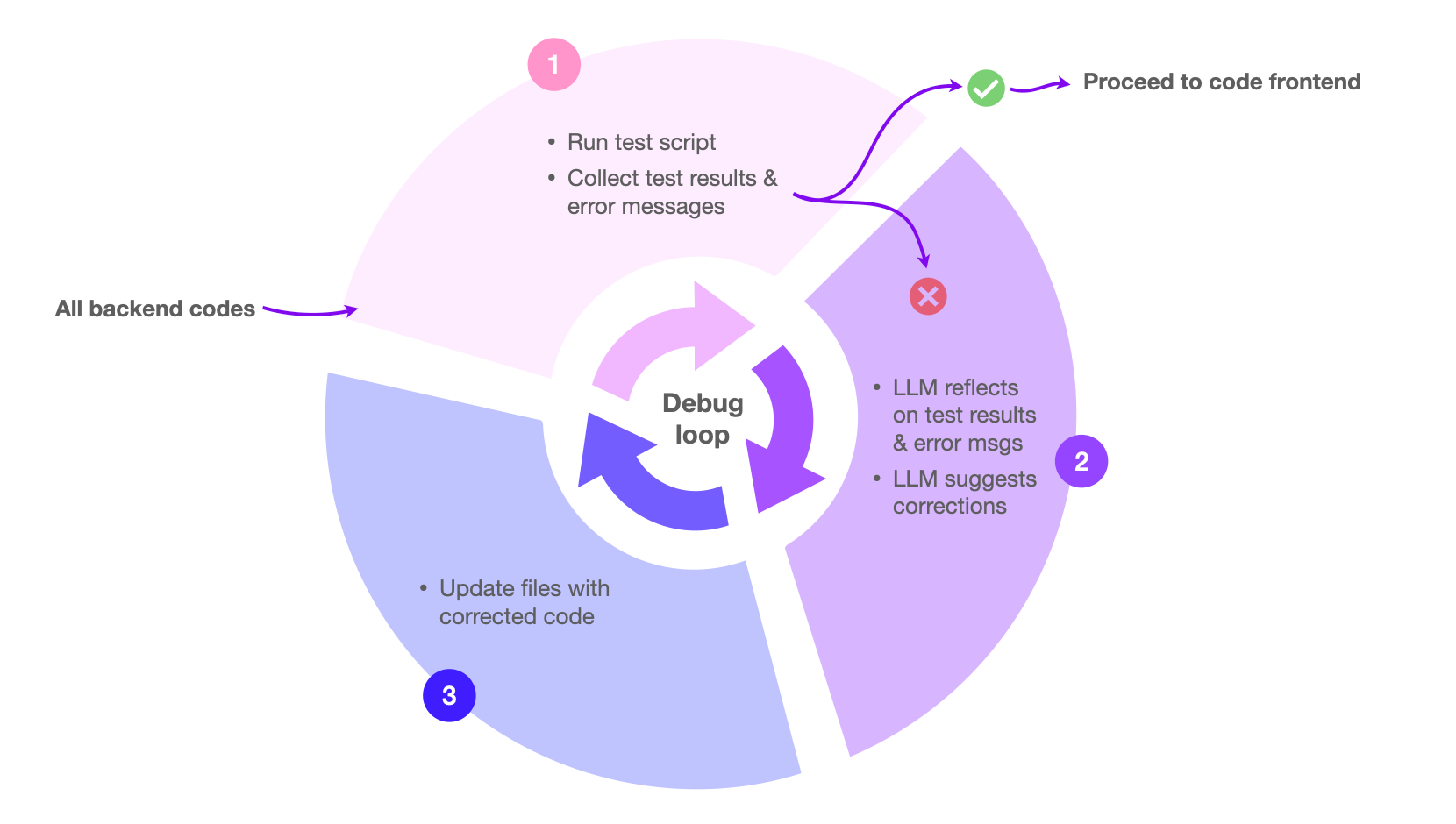
At first, I ran this with GPT 4o-mini. It hit a dead end almost from the very beginning. As you can see from the summary table below, LLM keeps reflecting on the same test failure reasons and couldn’t correct the source code to fix this error after 5 iterations.

Now let’s look at o1-mini’s performance:

On start, o1-mini identified the same problem as GPT 4o-mini, but it could correct the source code effectively such that in round 2, it faced a completely different cause for failure. In iteration 3 it started passing tests and in round 4 it cleared all 5 tests!
I also tested out Qwen2.5-Coder-32B-Instruct, which ranked #3 in the coding leaderboard, just after o1-preview and o1-mini. Below is the result. It started off as very promising; qwen could identify different bugs in different rounds. However, it definitely lacks the code correcting power of o1-mini, as the same issue lingered on from iteration 6 onwards. I ran this loop till iteration 12 and all tests consistently failed.

That’s about it for part 2 of this series. My takeaway from these tests, o1 is by far the smartest model out there in the market today. And looking at how the state of art in LLM evolved from seemingly clever but fundamentally clueless (e.g. 4o-mini) to reassuringly smart and astoundingly fast (e.g. o1-mini) makes me immensely excited about possibilities in the near future.